
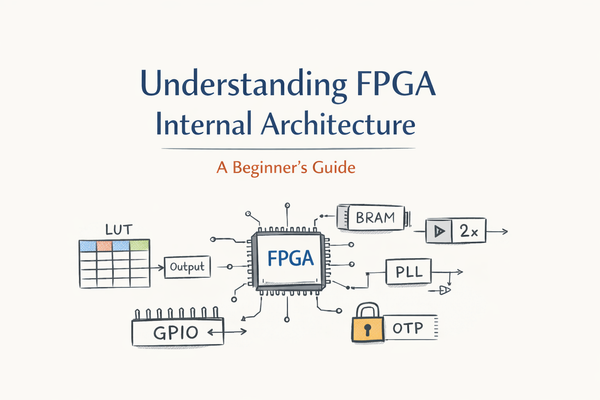
Understanding FPGA Internal Architecture : With Shrike
When people first hear the word FPGA, it often sounds intimidating—something abstract, complex, and very different from CPUs or microcontrollers. In reality, an FPGA is built from a small number of simple digital blocks, repeated many times and connected together in a programmable way. In this log , we’ll
